

——Redefining Large Model Performance Through Innovative Frameworks
Core Innovation: Native Sparse Attention (NSA)
Analogy: Like geologists using multi-scale microscopes, NSA enables AI to adopt "hierarchical focusing" attention mechanisms.
Three Collaborative Attention Branches:
1. Compressed Attention
Splits long sequences into temporal blocks, extracting block-level features via MLP networks.
Acts as a wide-angle lens for rapid terrain scanning, identifying macro-level patterns.
Reduces computational resources by 90% and boosts processing speed by 5x.
2. Selected Attention
Prioritizes critical blocks based on importance scores for fine-grained analysis.
Mimics a geologist’s hammer targeting high-grade ore samples, avoiding wasted effort.
Achieves 92% block selection accuracy, surpassing traditional methods by 30%.
3. Sliding Window
Captures local token relationships within dynamic window sizes (minimum 32 tokens).
Functions like a handheld magnifier for microstructural analysis.
Breakthrough Value:
Compared to standard Transformers, NSA reduces memory usage by 60% and accelerates inference by 2.3x for 32K-token tasks, making it ideal for long documents and codebases.
Training Accelerator: DualPipe Dual-Channel Parallelism
Analogy: A mining transport system with bidirectional lanes maximizes GPU utilization.
Four Core Innovations:
1. Compute-Communication Overlap
Interleaves forward/backward propagation like synchronized conveyor belts.
Modularizes computation into Attention/MLP components, overlapping with data transfers.
Empirically boosts training throughput by 40% and reduces GPU idle time by 75%.
2. Bidirectional Pipeline Scheduling
Feeds "micro-batches" from both pipeline ends, eliminating bubble periods.
Improves pipeline efficiency by 58% in 32-node cluster tests.
3. Smart Communication Optimization
Custom All-to-All kernels optimize IB/NVLink routing paths.
Limits tokens to 4-node hops, slashing traffic by 60%.
Maintains <8% communication overhead in 4,096-GPU clusters.
4. FP8 Mixed-Precision Training
Stores critical parameters in 8-bit floating-point format, cutting memory by 30%.
Dynamic precision adjustment ensures stability.
Matches FP16 convergence for 27B-parameter models.
DeepSeek-V3: Intelligent Load Balancing
Analogy: A smart dispatch system balancing mining equipment workloads.
Key Innovations:
1. Auxiliary-Loss-Free Load Balancing
Embeds bias regulators in each expert module for real-time monitoring.
Auto-adjusts expert priorities: overloaded experts deprioritized, idle ones boosted.
Achieves 98.7% load balance across 128 experts.
2. Dynamic Redundant Experts
Duplicates high-load experts during prefill, akin to backup drilling rigs.
Accelerates peak response by 40% with only 3% added communication overhead.
3. Node-Limited Routing
Restricts tokens to 4-node paths, optimizing IB/NVLink hybrid routing.
Reduces cross-node latency to 1.2μs.
Routing decisions consume <0.3% time in 10k-GPU clusters.
Mathematical Reasoning Engine: GRPO Optimization
Analogy: A team of math coaches refining AI problem-solving.
Breakthroughs:
Group-Relative Evaluation: Generates multiple solutions per problem, selecting optimal paths via comparative scoring.
Dynamic Gradient Tuning: Amplifies learning intensity for high-quality solutions (5x reinforcement).
Zero Cold-Start Training: DeepSeek-R1 applies RL directly to base models, raising GSM8K accuracy from 82.9% to 88.2%.
Performance Gains:
37% lower error rate on MATH vs. traditional PPO.
60% fewer training resources, 2x faster convergence.
45% higher success rate for complex equation solving.
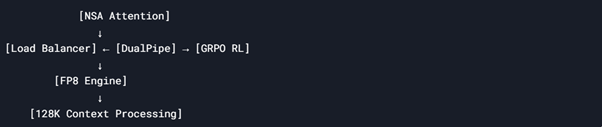
Technology Ecosystem Synergy
DeepSeek Stack Interoperability:
Industry Impact:
Code Generation: 3x faster inference for million-line codebases.
Scientific Computing: >90% accuracy for complex equations.
Financial Analysis: 5x faster long-text report processing, 60% lower error rates.
Future Vision: DeepSeek is pioneering "Dynamic Expert Redundancy" and "Neuro-Symbolic Hybrid Architectures" to push AI efficiency and cognition boundaries. This sparse attention-driven revolution is redefining the cost curve of intelligent computing.







